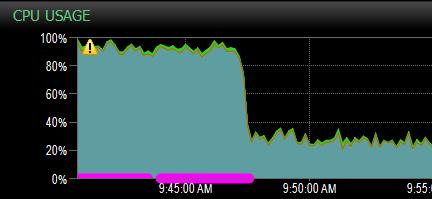
This image is an actual screen shot of one of our production SQL Server’s CPU usage, taken from our SQL Sentry monitoring system. Obviously this server was under some strain. Users were complaining that queries were taking 30+ seconds to run when they normally returned data in milliseconds. It eventually reached a point to where applications were timing out because queries were taking so long. After doing some analysis in SQL Sentry, we were able to determine what was causing the CPU spike, and came up with 3 nonclustered indexes to add to help alleviate the pressure. The screen shot you see here is what happened after I added the first index.
Just 1 Index.
In some of my presentations I have often quoted Microsoft as saying “proper indexing is the best performance enhancement you can make to a database.” I originally found this quote in the documentation for an older and long forgotten version of SQL Server, but I honestly believe that statement still holds true today.
Indexing is powerful. Very powerful. Yet even though it is one of the best performance enhancements you can make, it is very often misunderstood or even completely overlooked by developers. I have seen databases with no indexes whatsoever. I have seen databases with indexes on every individual column in the tables. I have seen OLTP databases with 60+ indexes on a single table because every time a recommendation showed up in SSMS is was put into production (this can be bad, as there are costs associated with indexes). I once saw a SQL Server that had an agent job to check for and delete every index in a multi-terabyte database because the “Architect” was absolutely convinced he could get better performance out of hardware than by using indexes. I have also seen an agent job that would automatically create everything it found in the missing indexes DVM.
I will admit, when I was a developer I didn’t really understand indexes either. I never bothered to read up on what they actually did, or how SQL Server used them, or how to even check and see if the indexes I created were being used at all. I was too busy writing code, and viewed the database as nothing more than a container that held data. I look back on those databases and applications that we were trying to squeeze every ounce of performance out of and wish that I had taken the time to learn and apply proper indexes.
If you are tasked with building databases, or even writing queries against existing databases, I urge you to take the time to learn a little bit about proper indexing. It can be a game changer for your career, taking you from a “query writer” to a “performance tuner”. Here is a quick primer I wrote on the differences between Clustered and Nonclustered indexes. If you want more details (and you should) then here are some good articles to get you well on your way:
- Clustered and Nonclustered Indexes Described (MSDN)
- GUIDs as PRIMARY KEYs and/or the clustering key
- Ever-increasing clustering key – the Clustered Index Debate……….again!
- SQL Server Index Design Guide (Technet)
- Create Nonclustered Indexes (MSDN)
- Understanding SQL Server Indexing
Then, if you’re really serious about taking your indexing and performance tuning to the next level, sign up for some training with SQLSkills or Brent Ozar. You’ll be glad you did. I was.
Pingback: Just One Well-Placed Index – Curated SQL